As you probably know, I’m a big fan of Akka. Akka Cluster is a great low-level mechanism for building reliable distributed systems. It’s shipped with powerful abstractions like Sharding and Singleton.
If you want to start using it you should solve cluster bootstrapping first. Almost every tutorial on the internet (including the official one) tells you to use seed nodes. It looks something like this:
akka.cluster.seed-nodes = [
"akka.tcp://ClusterSystem@host1:2552",
"akka.tcp://ClusterSystem@host2:2552"
]but wait… Hardcoding nodes manually? Now when we have Continuous Delivery, Immutable Infrastructure, tools like CloudFormation and Terraform, and of course Containers?!
Well, Akka Cluster also provides programmatic API for bootstrapping:
scala1def joinSeedNodes(seedNodes: Seq[Address]): UnitSo, instead of defining seed nodes manually we’re going to use service discovery with Consul to register all nodes after startup and use provided API to create a cluster programmatically. Let’s do it!
TL;DR
You can find the demo project here: https://github.com/sap1ens/akka-cluster-consul. It’s very easy to try (with Docker):
$ git clone https://github.com/sap1ens/akka-cluster-consul.git
$ docker-compose upDocker Compose will start 6 containers:
- 3 for Consul Cluster
- 3 for Akka Cluster
Everything should just work and in about 15 seconds after startup you should see a few Cluster is ready! messages in logs - it worked!
More details below ;-)
In depth
Service
First of all I want to explain what this demo service does.
I implemented simple key-value in-memory storage with the following interface:
scala1sealed trait KVCommand
2case class Get(key: String) extends KVCommand
3case class Set(key: String, value: String) extends KVCommand
4case class Delete(key: String) extends KVCommandSo we can set, get and delete string values. All these actions are exposed via HTTP API:
- GET http://localhost/api/kv/$KEY
- PUT http://localhost/api/kv/$KEY/$VALUE
- DELETE http://localhost/api/kv/$KEY
This simple functionality is going to be started as a Cluster Singleton. It means that Akka Cluster will make sure to keep only one copy of the service running. If the node with the service fails Akka Cluster will start the service in another node and forward all in-flight messages there. So it’s great for high availability and resiliency.
Service Discovery with Consul
To be able to use Consul we need to implement two things:
- Service registration. Every node with a running service should report about itself to Consul. Usually it’s done using Consul Agents, but in our case we’re going to use Consul HTTP API for simplicity. We use a shell script to simply hit Consul
/v1/catalog/registerAPI endpoint with required metadata and run the app. - Service catalog. We need to fetch a list of service nodes before calling
joinSeedNodesmethod. Our app uses OrbitzWorldwide/consul-client Java Client, so resulted code is very straightforward:
1import akka.actor.{ActorSystem, Address}
2import com.orbitz.consul.option.{ConsistencyMode, ImmutableQueryOptions}
3import com.sap1ens.utils.ConfigHolder
4
5import scala.collection.JavaConversions._
6
7object ConsulAPI extends ConfigHolder {
8
9 val consul = com.orbitz.consul.Consul.builder().withUrl(s"http://${config.getString("consul.host")}:8500").build()
10
11 def getServiceAddresses(implicit actorSystem: ActorSystem): List[Address] = {
12 val serviceName = config.getString("service.name")
13
14 val queryOpts = ImmutableQueryOptions
15 .builder()
16 .consistencyMode(ConsistencyMode.CONSISTENT)
17 .build()
18 val serviceNodes = consul.healthClient().getHealthyServiceInstances(serviceName, queryOpts)
19
20 serviceNodes.getResponse.toList map { node =>
21 Address("akka.tcp", actorSystem.name, node.getService.getAddress, node.getService.getPort)
22 }
23 }
24}Our Consul UI will look like this in the end:
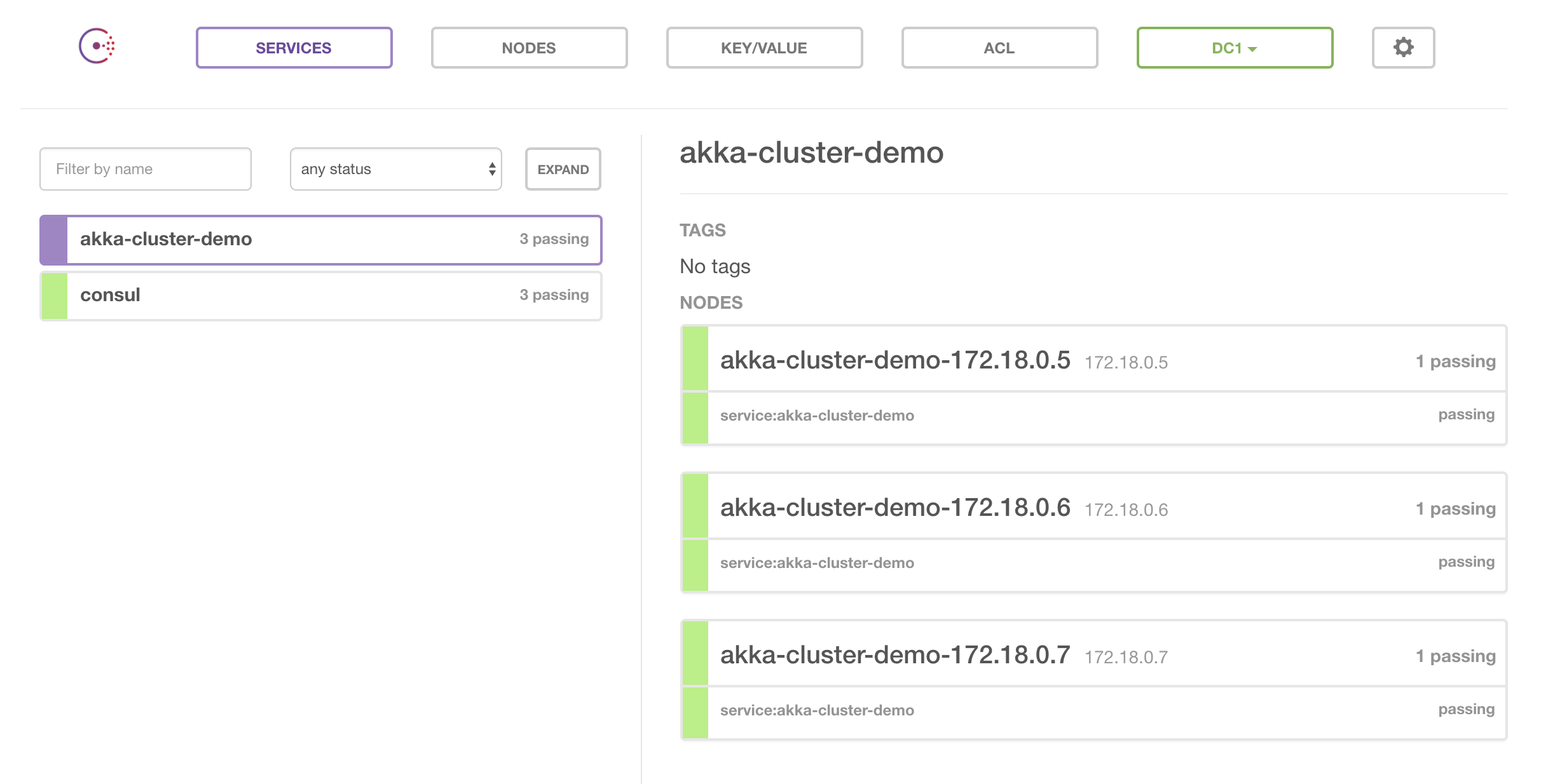
Akka Cluster Setup
Akka Cluster needs quite a few configuration settings, but the most important are these two:
min-nr-of-members = 3min-nr-of-members guarantees that cluster won’t be created until at least N nodes are joined.
akka.remote.netty.tcp {
# in production should be replaced with PUBLIC ip/hostname
hostname = ${HOST_INTERNAL_IP}
port = 2551
# Temporary, only for running real cluster locally with Docker
port = ${?SERVICE_AKKA_PORT}
bind-hostname = ${HOST_INTERNAL_IP}
bind-port = 2551
# Temporary, only for running real cluster locally with Docker
bind-port = ${?SERVICE_AKKA_PORT}
}akka.remote.netty.tcp contains networking configuration for our cluster, which looks a bit complicated (but it should make more sense when you look at the second part of the Docker Compose file).
So, Akka Cluster needs dedicated TCP port for its gossip protocol. Since we run multiple Docker containers on the same machine we have to dedicate different ports for different containers. In our case first node will use port 80 for HTTP API and port 2551 for gossip, second node will use port 81 for HTTP API and port 2552 for gossip and the third node will use port 82 for HTTP API and port 2553 for gossip, accordingly. In production you might simplify it if every service is running on a separate machine, you just need one port everywhere.
More explanation about port and hostname values can be found here.
Finally, let’s look at the cluster bootstrapping logic:
scala 1val cluster = Cluster(system)
2val isConsulEnabled = config.getBoolean("consul.enabled")
3
4// retrying cluster join until success
5val scheduler: Cancellable = system.scheduler.schedule(10 seconds, 30 seconds, new Runnable {
6 override def run(): Unit = {
7 val selfAddress = cluster.selfAddress
8 logger.debug(s"Cluster bootstrap, self address: $selfAddress")
9
10 val serviceSeeds = if (isConsulEnabled) {
11 val serviceAddresses = ConsulAPI.getServiceAddresses
12 logger.debug(s"Cluster bootstrap, service addresses: $serviceAddresses")
13
14 // http://doc.akka.io/docs/akka/2.4.4/scala/cluster-usage.html
15 //
16 // When using joinSeedNodes you should not include the node itself except for the node
17 // that is supposed to be the first seed node, and that should be placed first
18 // in parameter to joinSeedNodes.
19 serviceAddresses filter { address =>
20 address != selfAddress || address == serviceAddresses.head
21 }
22 } else {
23 List(selfAddress)
24 }
25
26 logger.debug(s"Cluster bootstrap, found service seeds: $serviceSeeds")
27
28 cluster.joinSeedNodes(serviceSeeds)
29 }
30})
31
32cluster registerOnMemberUp {
33 logger.info("Cluster is ready!")
34
35 scheduler.cancel()
36
37 init()
38}Here we create a scheduler to retry our attempts every 30 seconds with initial 10 seconds delay. It can be useful if Consul is not immediately available. Then we receive a list of service addresses from Consul and convert them to a list of seed nodes, using a few simple rules:
- Consul always returns nodes in the same order
- First node will always join with itself to form the initial cluster. Read a comment for more details
When cluster is established, init method is called. It contains all cluster-specific logic, like creating Singletons or Sharding. In our case it creates Cluster Singleton for our KVStorageService:
1system.actorOf(ClusterSingletonManager.props(
2 singletonProps = KVStorageService.props(),
3 terminationMessage = KVStorageService.End,
4 settings = ClusterSingletonManagerSettings(system)),
5 name = "kvService")
6
7kvService = system.actorOf(ClusterSingletonProxy.props(
8 singletonManagerPath = s"/user/kvService",
9 settings = ClusterSingletonProxySettings(system)),
10 name = "kvServiceProxy")So when you see Cluster is ready! message you can try the HTTP API! You can use any of our nodes (localhost:80, localhost:81, localhost:82), any node will know where Singleton instance is located and forward request-response if needed. Magic :)
Summary
As you can see, this setup is not particularly challenging, but it gives great benefits - we shouldn’t worry about bootstrapping cluster manually anymore. Consul is great for starting with service discovery, so this approach should be safe for introducing service discovery to your system.
Our solution will also work for rolling deployments and cluster resize.