Change data capture is a powerful technique for consuming data from a database. Modern solutions like Debezium leverage native WAL abstractions like MySQL binlog or Postgres replication slots to get data reliably and fast.
CDC Connectors for Apache Flink is an open-source project that provides tools like Debezium in native Flink source APIs, so it can be easily used in any Flink project. This blog post contains the lessons learned regarding working around some of the Flink CDC limitations and how they affect the overall Flink application design, as well as different gotchas related to the connector setup and configuration.
Also, I’ll target Postgres database specifically, but many insights here can be applied to other databases as well.
Why use CDC?
I’m not going to repeat many excellent resources on this topic. Instead, if you’re still not convinced refer to the Debezium FAQ and an excellent collection of CDC and Debezium resources.
Flink CDC vs Kafka Connect Debezium
Typically Debezium is executed as a Kafka Connect connector, which means, just to start you need to have running Kafka and Kafka Connect clusters. Then, if you want to do some processing on the data you’d also need to add a stream-processing engine like Kafka Streams or Apache Flink.
But it’s possible to run Debezium engine as an embedded application. From documentation:
Debezium connectors are normally operated by deploying them to a Kafka Connect service, and configuring one or more connectors to monitor upstream databases and produce data change events for all changes that they see in the upstream databases. Those data change events are written to Kafka, where they can be independently consumed by many different applications. Kafka Connect provides excellent fault tolerance and scalability, since it runs as a distributed service and ensures that all registered and configured connectors are always running. For example, even if one of the Kafka Connect endpoints in a cluster goes down, the remaining Kafka Connect endpoints will restart any connectors that were previously running on the now-terminated endpoint, minimizing downtime and eliminating administrative activities.
Not every application needs this level of fault tolerance and reliability, and they may not want to rely upon an external cluster of Kafka brokers and Kafka Connect services. Instead, some applications would prefer to embed Debezium connectors directly within the application space. They still want the same data change events, but prefer to have the connectors send them directly to the application rather than persist them inside Kafka.
And this is exactly what Flink CDC does! And that’s why, to start, you just need Apache Flink… and that’s it. So, you don’t even need Kafka in order to use it, which blew my mind the first time I realized it. And with Flink, you get solid fault tolerance, reliability and scalability guarantees. It seems obvious to me that when using Flink you should choose Flink CDC over Debezium Kafka Connect connector, unless, of course, 1) you already have Kafka and 2) you already have Kafka Connect and 3) you want to persist raw data in a topic.
Limitations
Flink CDC comes with a few limitations:
- Checkpoints are not allowed during the snapshotting phase. This means that, unfortunately, it’s not possible to pause and resume during snapshotting. This can be somewhat problematic when snapshotting large databases: an application restart will erase all progress. Also, depending on your checkpointing interval you should be ok with seeing some failed checkpoints until snapshotting is over, which could mean tweaking some monitors / alerts.
- Flink CDC source can only be run with a parallelism of 1. As far as I understand, this is because Debezium embedded engine uses a single thread for reading replicated messages. This means that there is an upper bound on the source throughput.
- Finally, there are some limitations related to the Postgres replication and using replication slots. You can find a section about this below.
Getting Started
The official documentation and the FAQ page are very helpful, so start there. You’ll also frequently consult with the Debezium documentation (currently Flink CDC uses Debezium 1.5.x, but 1.6.x upgrade is already available in the master branch), so open that as well.
Database Configuration
Flink CDC currently claims to support Postgres versions 9.6, 10, 11, and 12, however, I’ve been using 13 without any issues.
You do need to change one server-level configuration option. Run SHOW wal_level and ensure it returns logical. If it doesn’t, you have to modify it and restart the server, there is no other way. If you’re using a cloud provider, e.g. AWS, you may need to do it differently. E.g. in AWS RDS, you’d change rds.logical_replication to 1.
Another thing to tweak is called table replica identity, which is configurable with a simple ALTER TABLE statement. If it’s not configured to FULL, Debezium will not able to receive full rows in case of UPDATEs and DELETEs, which will probably cause Flink CDC to fail (depending on the deserialization methods you use). Enabling full replica identity on a table with a lot of UPDATEs or DELETEs can affect performance, so test that thoroughly.
Now, if you only consume a fixed number of tables you can execute a few ALTER TABLE statements to modify replica identity once. But if your list of tables is frequently changing, I’d recommend implementing a simple check before the start of the Flink CDC source and programmatically executing ALTER TABLE statements if needed.
Connector Configuration
Connector configuration looks fairly straightforward, but it has a few tricky options.
First of all, decoding.plugin.name. There are so many options available, but if you’re on Postgres 10+ just use pgoutput. It’s natively supported by Postgres and you don’t need to install any additional plugins.
tableList actually should also contain schema names. So, public.table_name or my_schema.table_name.
slot.name is one of the most important options you configure and you’ll find a dedicated section on that below.
deserializer is another extremely important option that’s only relevant for the DataStream API. You’ll also find a section below for that.
Finally, it’s also possible to pass any Debezium property using debezium. prefix. Things you should definitely consider configuring here are:
- decimal.handling.mode, time.precision.mode and similar ones for other complex types. Depending on the APIs you use and the chosen deserializer the values provided by default can be very problematic to deal with.
- snapshot.mode I recommend using exported. Since Debezium 1.6 initial was changed to have the same behaviour and the exported is deprecated.
- snapshot.select.statement.overrides might be useful if you want to tweak queries that run during the snapshot phase (e.g. filtering out irrelevant data). More on this below.
Replication Slots
Debezium uses replication as a way to receive Postgres Write-Ahead-Log data. In order to use replication, a replication slot has to be created. Unfortunately, replication slots are not cheap: each new slot adds some overhead to the server and that’s why the default limit of slots is 10.
Postgres has pretty strict replication slot name requirements, they must only include lower-case letters, numbers, and the underscore. That, however, is the least important problem related to the slots…
Because the number of slots is limited, you’d want to try to minimize it. But it might not be very straightforward:
- When using SQL API you can only specify a single table to consume from, which means you have to allocate a slot per defined table.
- When using DataStream API it’s possible to specify multiple tables, which means reusing a single slot per multiple tables, but Flink CDC doesn’t provide a lot of useful deserializers in this case, you either get a string representation of the internal’s Debezium record or a JSON object.
I think it’s obvious why the latter approach would be preferred in the majority of use-cases. Even if you only plan to consume from 2-3 tables to start, the requirements may change in the future, so you might hit replication slot limitation pretty quickly.
Ordering Guarantees
When consistency is discussed in the context of the streaming systems, we typically focus on delivery guarantees: at-least-once, at-most-once, exactly-once. However, the ordering guarantees can be as important for some use-cases. Overall ordering guarantees depend on the ordering before the Flink CDC source connector (what happens in the database world) and after (what happens in the Flink application).
The Flink application part is somewhat straightforward:
- Flink CDC source always has parallelism of 1, so the ordering is unaffected.
- The first operator that has parallelism that’s different OR triggers a shuffle (e.g. keyBy) will change the ordering of data.
This means that we can preserve the ordering even with parallelism > 1, as long as we choose an appropriate key and perform a keyBy operation on it. When dealing with relational databases, it’s very common to have a primary key defined on a table, which is unique and typically doesn’t have big data skew, so it’s a perfect candidate for keyBy. And in the case of a Kafka sink (or other similar streaming engines), it would be easy to map Flink parallelism and keys to Kafka partitions and message keys.
The database world is less straightforward.
During the snapshotting phase, Debezium will simply perform SELECT * FROM $table query by default. Postgres doesn’t provide any ordering guarantees in this case, so you can get data in any order regardless of the defined primary keys. I found two viable solutions to overcome this:
- Overriding default queries using the snapshot.select.statement.overrides parameters, e.g.
SELECT * FROM $table ORDER BY $primary_keys. This can work really well on relatively small tables or even medium ones with tens of millions of records. This strategy is not going to work for large (100M+) tables though. - Applying a stateful filter operation on the source, using a monotonically increasing numeric field, e.g. version or a timestamp. Here’s an example of a simple RichFlatMapFunction that will only emit records with the same or larger versions:
1new RichFlatMapFunction[Record, Record] {
2 @transient
3 private var maxVersion: ValueState[Long] = _
4
5 override def open(parameters: Configuration): Unit = {
6 maxVersion = getRuntimeContext.getState(new ValueStateDescriptor[Long]("maxVersion", createTypeInformation[Long]))
7 }
8
9 override def flatMap(record: Record, out: Collector[Record]): Unit = {
10 val currentMax = maxVersion.value()
11 val recordMax = record.version
12
13 if (currentMax == null || recordMax >= currentMax) {
14 maxVersion.update(recordMax)
15 out.collect(record)
16 }
17 }
18}- You can also configure state TTL that’s larger than the typical duration of the snapshotting phase, guaranteeing that all required values will stay in the state during the snapshotting and then can be garbage-collected.
- Of course, this strategy means that some rows may not be emitted. But usually, when dealing with relational databases we’re interested in the latest version of a certain row anyway, so this strategy can work well.
When the snapshotting phase is finished and Debezium starts consuming live data, the ordering is pretty much similar to what the application interacting with the database sees. Keep in mind, that it’s normal to not have perfect ordering due to overlapping or long-running transactions.
Deserialization
JsonDebeziumDeserializationSchema is the only deserializer mentioned in the documentation. Because it emits a JSON string it’s very likely it’s not the last deserializer you’d apply, you’ll probably at least end up converting that JSON string into a POJO, a case class or a Row object. And this will be slow because you have to serialize/deserialize JSON twice. And if you decide on any kind of processing between these steps, add one more deserialization.
This becomes really wasteful if JSON is not your final format. E.g. if you want to use Flink’s Table API downstream from the source you need to get data into RowData/Row format.
I profiled a Flink CDC application that used JsonDebeziumDeserializationSchema and was shocked by discovering the percentage of CPU spent on JSON serialization/deserialization was 60% and higher (highlighted in purple):
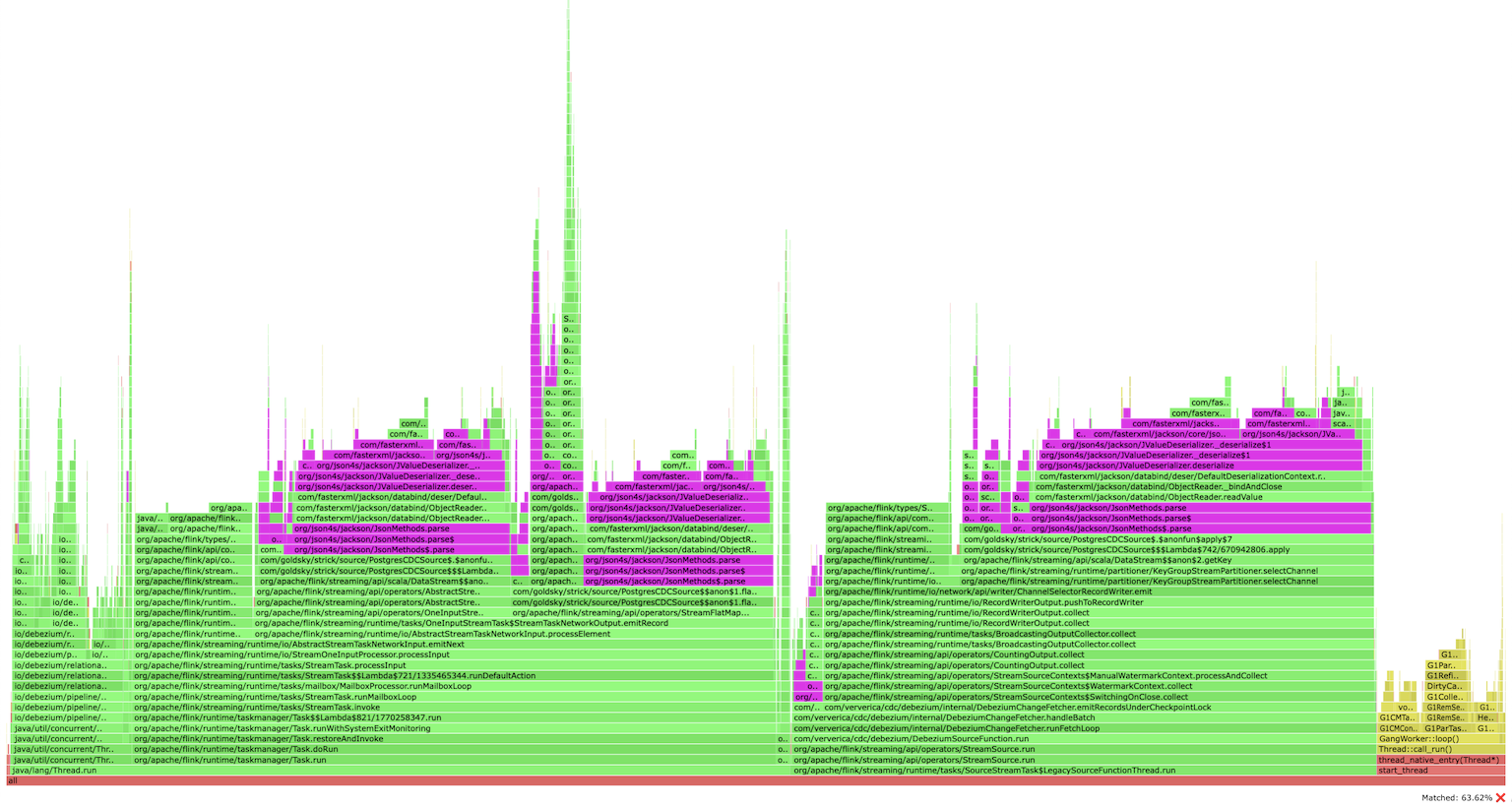
Swapping standard Jackson library with other more efficient ones didn’t help much. I’ve realized that the most efficient way would be to avoid any deserialization and process raw Debezium records as is (it uses Kafka Connect’s SourceRecords). But, even if you don’t apply any deserialization explicitly, Flink will try to serialize and deserialize them for network exchange, and since these records are not POJOs, Kryo deserialization would be chosen by default, which is also pretty slow. How can you avoid that?
Designing an Efficient Flink CDC Source
So, after realizing how slow SourceRecord deserialization can be and learning about replication slot limitations, I came up with the following design:
- Use DataStream API flavour of the Flink CDC Source, and subscribe to multiple tables. This allows you to re-use a single replication slot (which is as efficient as it can be 🙂).
- When specifying a deserializer just pass a raw “passthrough” one like this:
1class RawDebeziumDeserializationSchema extends DebeziumDeserializationSchema[SourceRecord] {
2 override def deserialize(record: SourceRecord, out: Collector[SourceRecord]): Unit = {
3 out.collect(record)
4 }
5
6 override def getProducedType: TypeInformation[SourceRecord] = {
7 createTypeInformation[SourceRecord]
8 }
9}- Now demultiplex a single DataStream of
SourceRecords from all tables into multiple DataStreams ofSourceRecords, one per table. This can be as simple as a FlatMap operator checking source Debezium metadata:
1def demultiplex(
2 tableIds: Seq[TableId],
3 sourceStream: DataStream[SourceRecord]
4): Map[TableId, DataStream[SourceRecord]] = {
5 tableIds map { tableId =>
6 (
7 tableId,
8 sourceStream
9 .flatMap(new FlatMapFunction[SourceRecord, SourceRecord] {
10 def flatMap(value: SourceRecord, out: Collector[SourceRecord]): Unit = {
11 val record = value.value().asInstanceOf[Struct]
12 val source = record.getStruct("source")
13 val recordSchema = source.getString("schema")
14 val recordTable = source.getString("table")
15 if (recordSchema == tableId.schema && recordTable == tableId.table) {
16 out.collect(value)
17 }
18 }
19 })
20 )
21 } toMap
22}TableIdin this case is a simple case class withschemaandtablefields.- We need to ensure no serialization happens between the source and the operator that will eventually process Debezium records. In order to do it, we can enable object reuse in Flink and set the parallelism of all intermediate operators (like the FlatMap above) to one. The latter change could be concerning, but since the parallelism of the source is always one, we’re just fusing all intermediate operators into one, which runs in a single JVM. This is quite efficient, there is no need to try to parallelize the serialization/deserialization process.
- In order to preserve the ordering guarantees, we can perform a keyBy operation using the primary key values. Optionally, we can also add a stateful filter like the one described in the Ordering Guarantees section if tables have monotonically increasing values.
- Dealing with raw
SourceRecords in the rest of the application is probably not what you want to do, so before performing the keyBy operation you could transform them to a different format. For example, when using Table API you can transform them to RowData objects using theRowDataDebeziumDeserializeSchema. You can’t useRowDataDebeziumDeserializeSchemaat the source level, because this deserializer requires a specific data type and our source consumes from multiple tables with different schemas / data types. But demultiplexing step earlier helps with having a single schema / data type per DataStream. - Now, if the Table API is your goal you can create a
RowRowConverterfor converting RowData records into Row records and create the actual table usingStreamTableEnvironment.fromChangelogStream.
Summary
Debezium and Flink CDC are excellent projects, but Change Data Capture can be complex, so understand the challenges you’re facing. You should:
- Decide your replication slot strategy. The need to use Table API doesn’t mean you have to waste a slot per table.
- Decide your deserialization strategy and try to avoid useless intermediate deserialization/serialization steps.
- Understand the ordering guarantees you require and the ordering guarantees you get in different phases of the CDC source lifecycle (snapshotting vs live consumption).